SELECT a.FLD1, ..., b.FLD1,...
FROM TAB1 a, TAB2 b
WHERE a.KEY1 = b.KEY2
AND a.FLD1 = 'AB'
AND b.FLD2 = '10'1. Nested Loop Join : 어느 한쪽을 드라입밍 해서 조인하는 방식

: 실행 계획의 아이콘입니다. 중첩 루프 즉, for 루프 두 개를 연상하게 합니다.
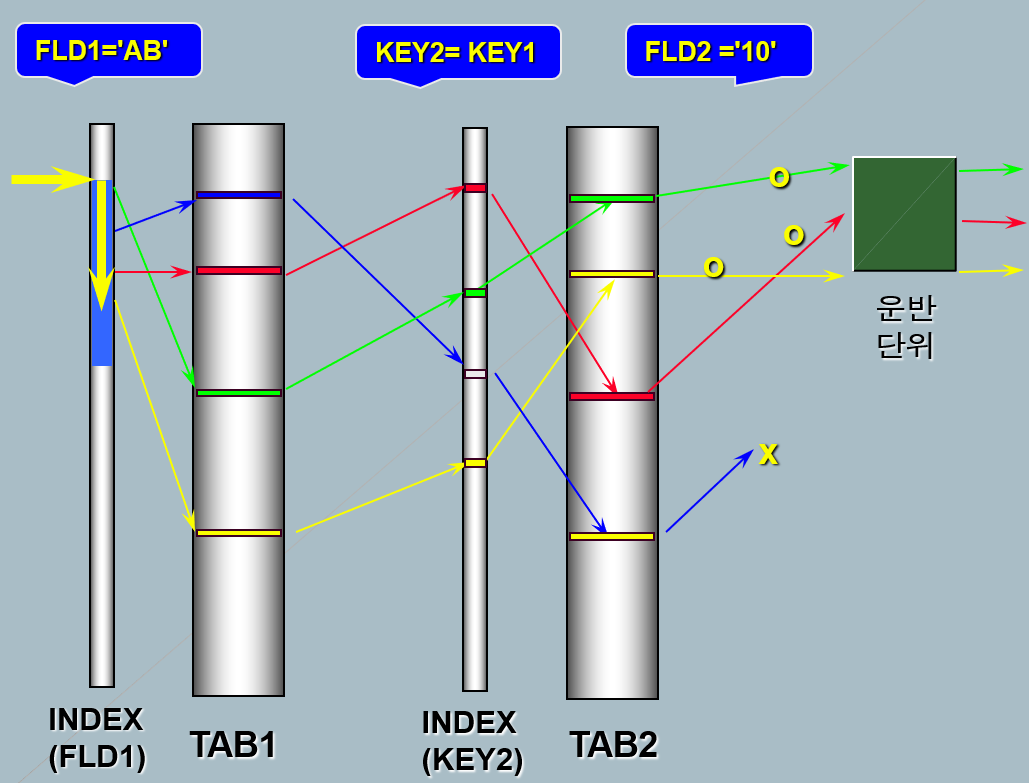
- 순차적 (부분범위처리 가능)
- 종속적 (먼저 처리되는 테이블의 처리범위에 따라 처리량 결정)
먼저 처리되는 테이블의 범위가 넓다면 더 많은 처리량이 생기는 거죠. - 랜덤 액세스 위주
- 연결고리 상태에 따라 영향이 큼(key2 = key1)
- 주로 좁은 범위 처리에 유리
2. Sort Merge Join : 테이블 각자 소트하여 머지 합니다.

: 양쪽 테이블을 읽어서 합치는 듯한 모양입니다. 재미 있죠.
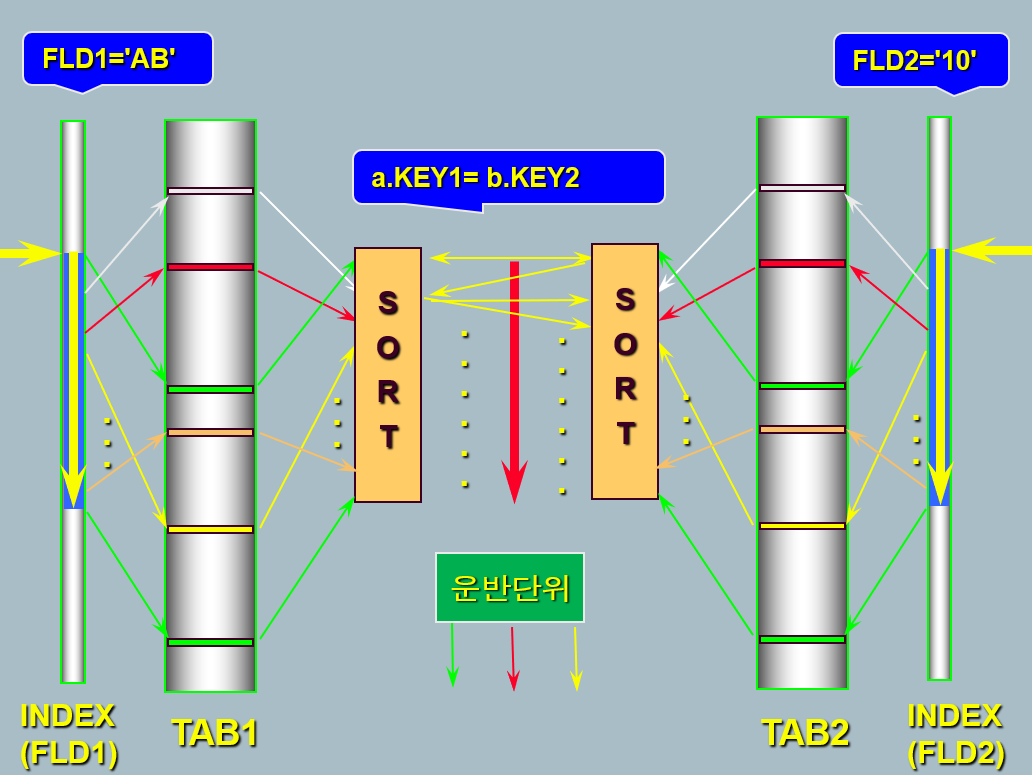
- 동시적 (무조건 전체범위처리)
Sort가 끝나야 Join을 하므로 전체 범위 처리입니다. - 독립적 (자기의 처리범위만으로 처리량 결정)
- 스캔(Scan) 액세스 위주
- 연결고리 상태에 영향이 없음
- 주로 넓은범위 처리에 유리
3. Hash Join : 동일한 해시 함수를 이용하여 해시 테이블을 만들고 일치하는 항목을 찾는 방법입니다.
:어떤 특정 값을 액세스하는 모양입니다.
Nested Loops가 랜덤 액세스에 대한 부담이 있더라도 적은 양의 데이터를 처리하기 좋습니다.
Sort Merge는 정렬의 부담은 있지만 연결고리에 이상이 있는 경우 대용량을 처리하기에 좋습니다. 정렬해야 할 양이 너무 많아지면 성능이 저하됩니다.
각 정렬의 단점에 대한 대안이 될 수 있는 것이 Hash Join 입니다.
각 테이블의 연결고리에 있는 인덱스를 사용하지 않습니다. 대신, 실시간 인덱스(해시 테이블)을 통해 조인을 합니다. 때문에 연결고리에 이상이 있어도 좋은 성능을 낼 수 있습니다. 조인의 결과는 별도의 Sort에 해당하는 동작이 없으므로 정렬되지 않습니다.
연결고리에 이상이 있거나 연결고리의 인덱스를 사용하지 못할때 사용하며 작은 데이터와 대량의 데이터를 조인할때 효과가 가장 좋습니다. 작은 테이블 읽어 메모리에 해시 테이블을 만들어 두고 큰 테이블을 읽으면서 해시 값을 비교를 계속해서 수행합니다.
Join의 동작 방식을 알고 용도에 맞게 사용하여야 겠습니다.
최종 정리
- Nested Loops Join : 적은 데이터와 적은 데이터 조인, 연결 고리 OK인 경우
- Sort Merge Join : 많은 데이터와 많은 데이터 조인, 연결 고리 NO인 경우
- Hash Merge Join : 적인 데이터와 많은 데이터 조인, 연결 고리 NO인 경우
'서버 개발 > 데이터베이스 일반' 카테고리의 다른 글
| RDBMS의 정규화 단계 (0) | 2025.03.28 |
|---|---|
| [MSSQL] 데이터 저장 구조 (0) | 2020.05.03 |
| OLTP, OLAP, DW (0) | 2020.03.25 |
| SQL의 분류 DML/DDL/DCL/TCL (0) | 2020.03.25 |